Project information
- Course: ECE 4750 — Computer Architecture
- Date: September 1 – December 18, 2024
- Language: Verilog HDL
- Tools: PyMTL, RTL simulation, execution trace analysis
Summary
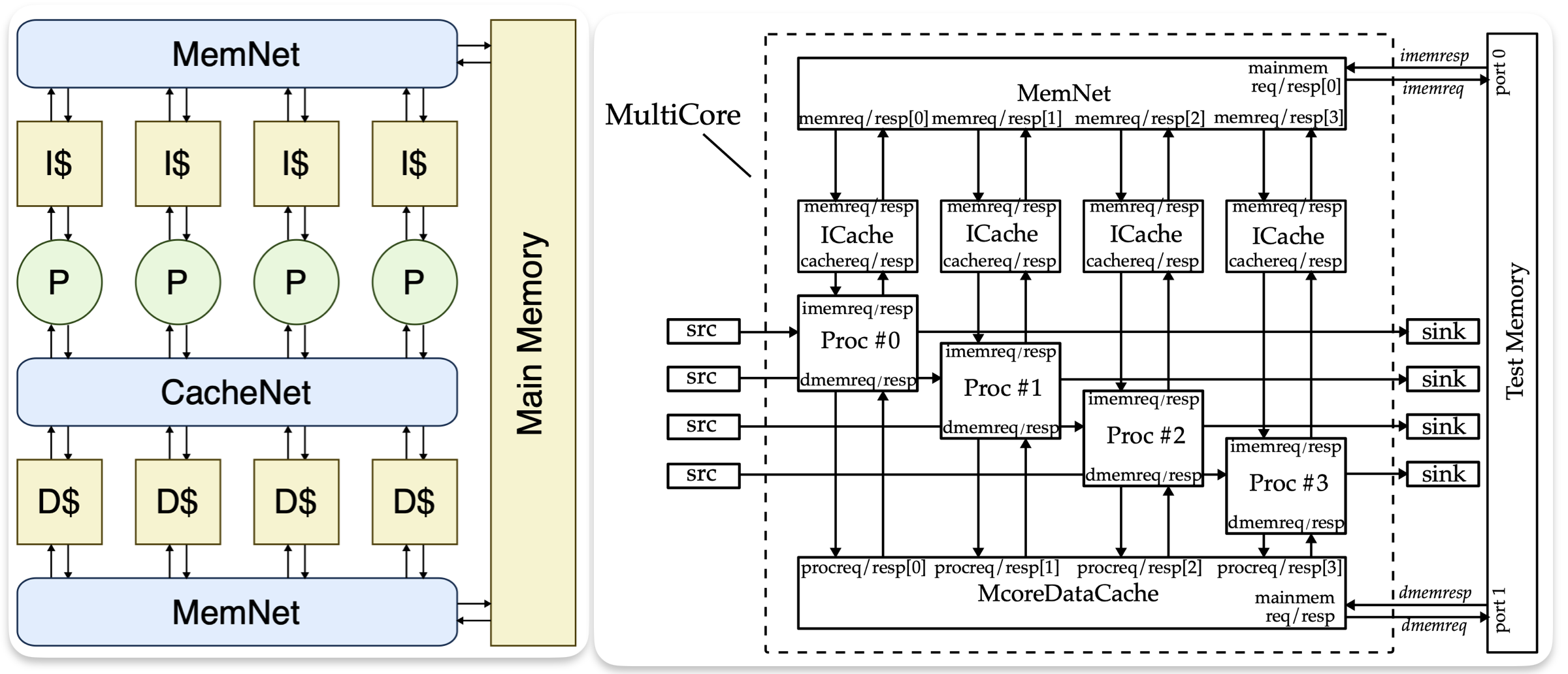
As the culminating design project for Cornell's Computer Architecture course (ECE 4750), I designed and implemented a multicore, pipelined RISC-V processor in Verilog HDL. The project spanned the full semester and covered each major component of a modern CPU from scratch.
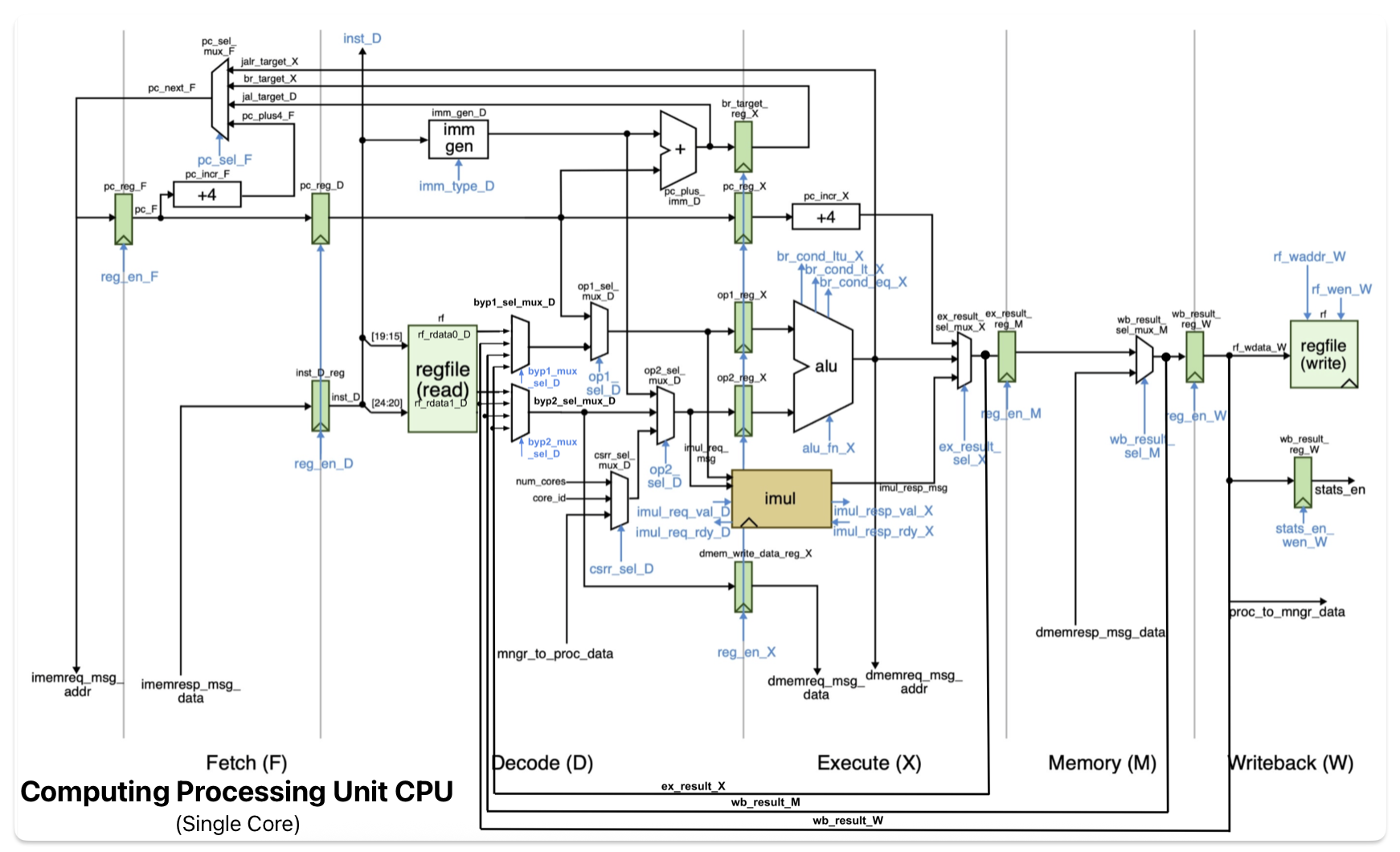
Pipeline & Hazard Handling
The processor implements a 5-stage pipeline (IF → ID → EX → MEM → WB) with full bypassing (forwarding) to handle data hazards without stalling. Bypassing reduced execution time by approximately 50% compared to the stall-only baseline. Load-use hazards require a single stall cycle; control hazards are handled with a flush on taken branches.
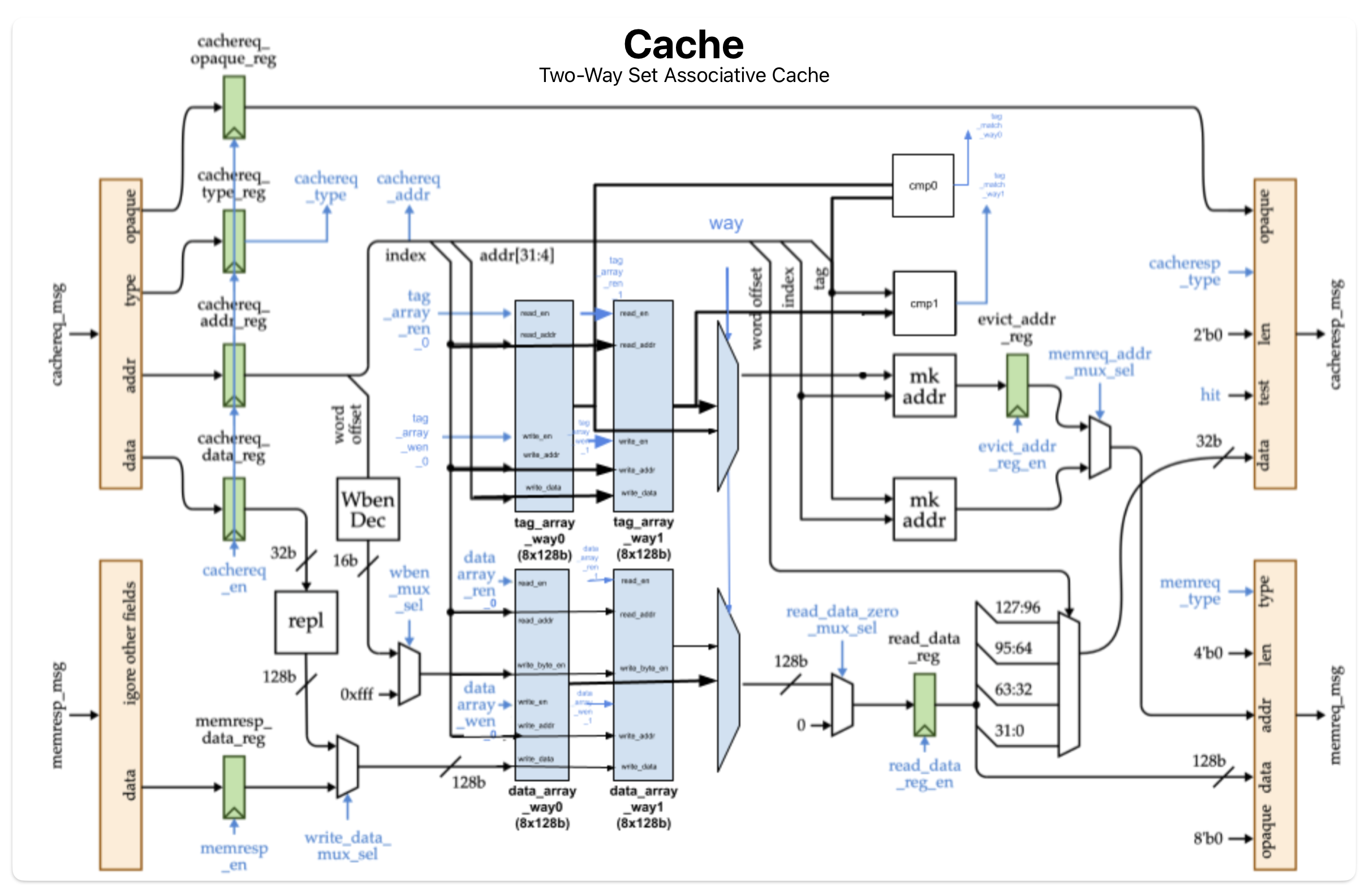
Memory & Cache
A custom direct-mapped instruction and data cache was designed and integrated to reduce average memory access latency. The cache design explored area/energy/speed trade-offs across different line sizes and associativity configurations.
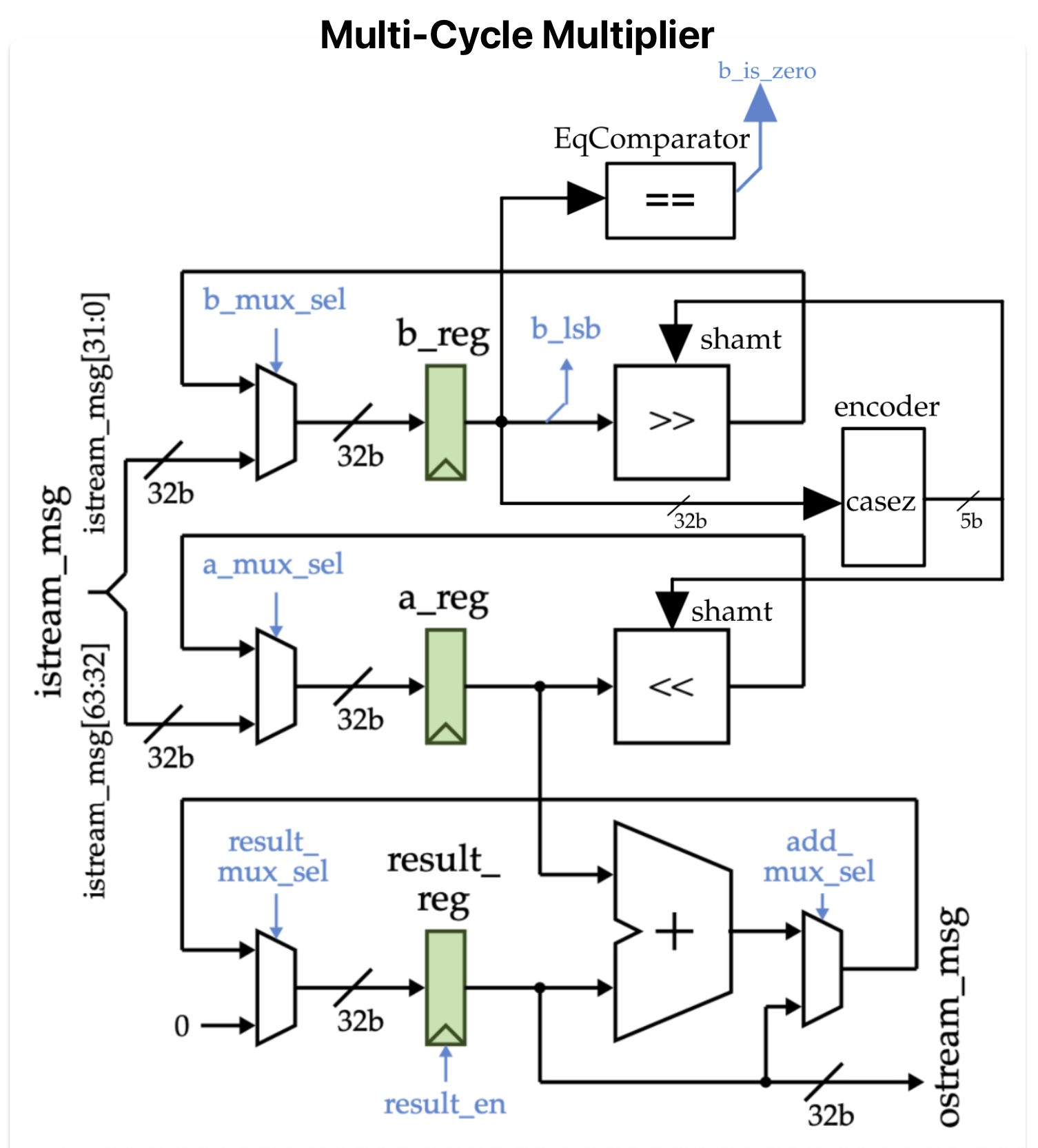
Multi-cycle Operations & Verification
A multi-cycle integer multiplier was implemented to handle MUL instructions without a single-cycle critical path blowup. Functional correctness was verified end-to-end using Python-based testbenches in PyMTL, including hazard stress tests and execution trace comparison against a reference ISA simulator.